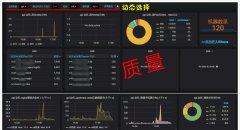
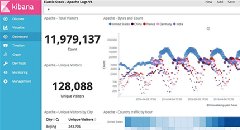
Nginx有两套日志,一套access.log一套error.log,access.log是可以用户自定义,两套日志处理好,业务的质量就了然于心了,另外,日志关键指标可视化分析我认为是运维中最重要的事情了,没有之一...
2019-05-13 798℃ 矢量bit 5 喜欢
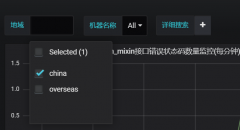
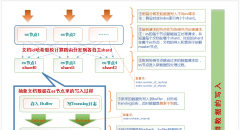
有这么一种场景,grafana同一个dashboard需要进行多个业务切换查看不同指标的变化,或从idc看到单个或某几个host,其实就是关联钻取,进而进行问题的分析,zabbix是可以实现的,但用e...
2019-01-16 937℃ 矢量bit 8 喜欢
服务器、应用程序、业务的健康情况和产品的各运营指标都藏在服务器产生的数据里,运维使用这些数据可以做成服务质量、服务性能、服务容量的监控告警,也可为运营部门出各种...
2018-06-19 868℃ 矢量bit 8 喜欢
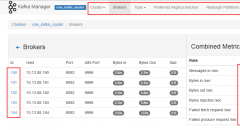
在elk集群搭建过程中,为了极大程度的利用服务器资源,kafka、zookeeper、logstash规划混跑在了同一组服务器上。随着业务量的增加,要频繁增加调整kafka的topic,出现问题时还要去服务器敲命令查...
2018-05-24 3225℃ 矢量bit 34 喜欢
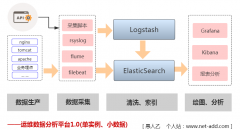
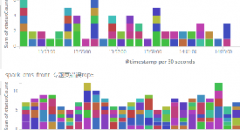
实时日志分析作为掌握业务情况、故障分析排查的一个重要手段,目前使用最多最成熟的莫过于ELK方案,整体方案也有各种架构组合,像(Rsyslog/filebeat/...)->Elastic->Kibana、(Rsyslog/filebeat/...)->Redis...
2018-04-15 9550℃ 矢量bit 146 喜欢
logstash在整个日志分析方案中起到了数据清洗的作用,在向es推数据时一个很重的细节是timestamp的设定,如果按照流时间走默认值,是不利于后期的分析的,所以需要通过各种方式将日志...
2017-12-13 1903℃ 矢量bit 3 喜欢
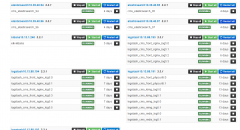
随着日志量的增加,es在不停的调整,结构层面的冷热数据分离、master和client节点的分离并引入部落节点,es集群层面的index优化、flush优化、merge优化、内存熔断优化,系统层面的GC、文...
2017-08-16 1962℃ 矢量bit 36 喜欢
业务中通过rsyslog监控本地文件收集了一些redis和mc的慢日志,推到elk集群分析,这些日志一天一个文件,每晚零点5分通过计划任务用软连接的方式将新的文件固定到指定文件下,但是最...
2017-06-13 1038℃ 矢量bit 12 喜欢
ES老集群用的2.4.1版本,跑的比较好就一直没动,最近看资料ES5.X已经稳定,并且性能有较大提升,心里就发痒了,但由于业务要保持高可用的属性,就得想一个平滑升级的方案,最后想到了多实...
2017-04-10 809℃ 矢量bit 11 喜欢