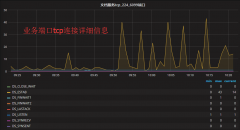
(目前测到86万,当然有大量长连接,每天打的日志高到170多g,不打算继续测了),业务系统为反向代理ATS,服务的内容为动态域名,大部分的url很长,不过打开后的值只是0或1这样的标记。
(目前测到86万,当然有大量长连接,每天打的日志高到170多g,不打算继续测了),业务系统为反向代理ATS,服务的内容为动态域名,大部分的url很长,不过打开后的值只是0或1这样的标记。
当服务器在几万并发时,一般不需要考虑TCP连接消耗内存的问题,但当服务器承载几十万并发时,会暴漏出各种的问题,因此不得不考虑TCP连接对内存资源的消耗,当然跑到86万的并发需要对业务系统、Centos做各种参数优化,牵涉面太多,今天只说TCP内存占用(由于线上系统干扰条件很多,无法特定的对某个参数去调试,只分享一下做过程的心得,抛砖引玉),出现的问题如下:

(内存不够用,kernel直接把ats的进程给杀掉了,然后out of socket memory)

(跑着跑着,直接out of socket memory)

(tsar的内存监控数据)
每一个TCP连接都会有对应的socket封装,而每个socket都要占用一个fd,现在的业务系统大都采用epoll的网络I/O模型,他可以高效的处理大批量socket句柄,而这个socket句柄的对应的TCP读写缓存再加上一个TCP控制块就是单个TCP连接所消耗的内存,当然这个读写缓存的大小是根据系统的需要动态变化的,和TCP的滑动窗口大小成正相关。
对于tcp能够使用多少缓存,centos是会有全局控制的,例如我线上的服务器(内存62G,有15个G做内存cache使用)。
TCP能够使用的内存:这三个值就是TCP使用内存的大小,单位是页,每个页是4K的大小,如下:

这三个值分别代表
Low:6179424 (6179424*4/1024/1024大概23g)
Pressure:8239232 (8239232*4/1024/1024大概31g)
High:12358848 (echo 12358848*4/1024/1024大概47g)
这个也是系统装后的默认取值,也就是说最大有47个g(75%的内存)可以用作TCP连接,这三个量也同时代表了三个阀值,TCP的使用小于第二个值时kernel不会有任何提示操作,当大于第二个值时进入压力模式,当高于第三个值时将不接受新的TCP连接,同时会报出“Out of socket memory”或者“TCP:too many of orphaned sockets”。
TCP读缓存大小,单位是字节:第一个是最小值4K,第二个是默认值85K,第三个是最大值16M,如下:

这个可以在sysctl.conf中net.ipv4.tcp_rmem中进行调整。
TCP写缓存大小,单位是字节:第一个是最小值4K,第二个是默认值64K,第三个是最大值16M,如下:

这个可以在sysctl.conf中net.ipv4.tcp_wmem中进行调整。
也就是说一个TCP在三次握手建立连接后,最小的内存消耗在8K左右,最大的内存消耗在32M左右,你可以通过MTU估算MSS,然后算出一个滑动窗口有多少个MSS。现在可以进行简单计算了,按照系统TCP的全局控制,有47个g可用作内存缓存,假设按照默认的读写缓存计算,一个TCP连接占用149K加1K的tcp控制块共150K的内存,那么系统能承受最大的并发为 47*1024*1024/150 = 32万,当然这只是理论,一个TCP连接占用的内存实际是大小混用的,根据传输的文件大小以及网络状况动态调整。那么当前是什么情况呢,是有很多的长连接,而且每个请求的数据都很小,也就是说很有大量TCP连接只占了10K左右的内存,所以可以尝试更大的并发。
好了,我顺着思路往下想,“Out of socket memory”除了业务系统恶意丢弃请求、或者孤儿套接字太多、或者fd(已经优化的很大了,不存在)用完了,就可能是为新的soket分配内存资源内存不够用了,因为在之前测试到30万左右的连接的时候出过这个问题,查看内存基本跑满,当时是把ats的logbuffer改小(动态连接一个url有时到45K的长度,于是当时把log buffer改的特别大)后就不报了,后来继续跑到50万左右又报错了,内存基本跑满,后把内存cache从30G调到了15G,再腾出15G给TCP连接及其与资源使用,跑到70万左右又不行了,大量这个错误。因为当前内存使用的很杂,有ats的内存缓存,有大量的孤儿Orphan soket(占用64K左右内存),还有大量的没有释放的TCP连接,还有ats的log等线程使用的内存,七七八八算下来,TCP能使用的内存不多,长连接、小链接、大链接的比例也不好计算,只能按照经验去尝试,目前看跑到70万已经到头了吧。
可是后来又想,系统对于刚开始建连接的时候可能是默认的内存占用,之后再动态调整,按照当前域名质量情况,大多数都是小的不能再小的请求,我是否可以更改默认TCP的读写缓存呢,于是调整,读写默认缓存各变为原来的一半分别是43K和32K,第二天晚高峰检查,跑到86万,没有出现问题,好了到此为止,不再测了。

总结:其实系统单纯能跑多大并发在乎全局fd和内存,但大并发下还能继续保持业务正常服务就是技术活儿了,每个业务系统的参数、操作系统的参数都得琢磨尝试,其余方面的优化小记有空再写。
“运维网咖社”原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 、作者信息和本声明。否则将追究法律责任。http://www.net-add.com

 |
社长"矢量比特",曾就职中软、新浪,现任职小米,致力于DevOps运维体系的探索和运维技术的研究实践. |