发展到现在,每天的日志量在15个亿左右,并引入了spark选手,业务越重,压力越大,es的index和search的优化一直是面临的最大考验,每次不合理的search带来index的延迟,甚至集群某些节点
发展到现在,每天的日志量在15个亿左右,并引入了spark选手,业务越重,压力越大,es的index和search优化一直是面临的最大考验,每次不合理的search带来index的延迟,甚至集群某些节点假死,在发现es的5.2.1版本有请求不能熔断的bug后,进行了小版本5.2.2版本升级,效果不佳,纠结后果断选择干脆升级最新的5.5.0版本,在所有优化项和优化参数(后面会对es从结构到优化的参数做一个介绍)未做调整的前提下,发现性能和稳定性提升很明显,同时还带来了一个很牛的功能机器学习,由于服务器是纯内网结构,升级过程自己搭建文件服务器,使用shell脚本进行的批量升级,当时使用supervisor管理服务,在这个时候就显示出尤其的方便,不展开说了,记录一下升级前后的数据对比。
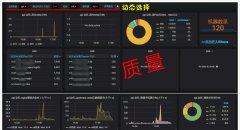
图一总体情况(特意等了4个小时再看的数据):

升级是在14:00,从x-pack图表来看,在升级瞬间indexing的速度稳稳的上去了,上扬的一下可能是要补升级瞬间kafka队列里积累的数据,但之后的表现与之前5.2.2版本的曲线形成一个很明显的对比,indexing数据在21000左右稳定下来了,取代了原来5.2.2版本不停的抖动;另外再看indexing时延,这个表现的更加明显,升级后没有大的抖动了;第三,仔细看search和indexing两张图的上下对比,发现18:00时search的上涨并未影响到indexing的性能,整体就是看到了一个性能更加稳定的曲线。
图二单个node节点gc:

从gc和heap来看,heap的使用率比之前总体下降,并且稳定下来,新生代gc的count有所上升,也是稳定的,也就是说同样业务下heap内存使用的少了。
这次升级总体来看,es5.5.0集群的表现就是一个字“稳”,性能在提升的同时稳定了下来,非常好。
“运维网咖社”原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 、作者信息和本声明。否则将追究法律责任。http://www.net-add.com

 |
社长"矢量比特",曾就职中软、新浪,现任职小米,致力于DevOps运维体系的探索和运维技术的研究实践. |