前记: 本文从SRE的角度白话诠释小爱的技术保障,也让大家对SRE有个近距离了解,里面有技术干货也有方法论干货,喜欢请转发拿走,目前AI-SRE对小爱的主治医师有文杰、小乔、超哥、
前记:本文从SRE的角度白话诠释小爱的技术保障,也让大家对SRE有个近距离了解,里面有技术干货也有方法论干货,喜欢请转发拿走,目前AI-SRE对小爱的主治医师有文杰、小乔、超哥、芬姐、兴耀、梁宇、恒硕、燕歌、矢量比特(高利绪),再次邀请你使用小爱同学,这个AI机器人绝对值得拥有,先来个小爱医师合照。

开题:对于用户而言,你看到的是小爱同学优美的外表,她穿着音箱、电视、手机等各种米系炫酷IoT设备的外衣,在各种场合闪亮登场;感受的是小爱同学可爱的灵魂,她能给你解闷和你聊天、帮你逗孩子、控制各种智能设备、播音乐、讲故事.......可以说是上天入地、无所不能。虽然偶尔也开一下小差(毕竟目前还是个3岁宝宝嘛),但整体来讲小爱同学可以说是一个劳模,你什么时候呼唤她,她都随时待命,并全身心和你沟通,帮你排忧解难,而且越来越懂你(小爱基因自带AI气质)。
有这样一个场景,当你出差离家几天或者更久,半夜赶车回到空荡荡的家中,倦意之下喊了一声“小爱同学”,一句清爽的“我在”马上给了应答,这时是多么的温暖,原来一直有个灵魂在陪伴着你,你并不孤独,这就是“小爱同学”,在会议室偶遇人形小爱身躯,看看是不是很美?

这是一个用户眼中的小爱,优雅而简单,但真相远非如此,真正的小爱同学其实是由成千上万台服务器组成,服务器之间用一根根网线连接,组成了小爱的物理神经系统,网卡信号灯不停的交替闪烁代表小爱在不断的思考交互,这些服务器分布在全国各地的机房中,固定在一个个铁框框机架位上,错综复杂实则有序,在IDC工程师的管理下,7*24小时不间断的运行着。
但仅有服务器还是远远不够的,服务器上跑着小爱工程师开发的各种程序,成千上万,这才是小爱的真身,每个程序都有独立的职责,为了管理我们把相关的程序放在一起形成模块,这些模块好比小爱的头、躯干、四肢、内脏、肌肉..........模块间相互协作,完成用户的一个个诉求,这样才有了现在聪明伶俐的小爱同学。
那么问题来了,是人都要生病,何况是如此庞大复杂的机械躯体?人头疼脑热的时候可以请假去医院,休息几天,但小爱是个商业产品,如果一头疼脑热就休息几天,恐怕用户都就没有了,作为工程师的我们如何保障他7*24小时的健康稳定呢?
1、给小爱三头六臂、千手千脚(灾备)
生病是难免的,特别小爱这么庞大的身躯,成千上万台的机器,gpu、cpu、内存、主板、硬盘.....任何一个零件故障就可能使一台服务器宕机罢工,这些年光纤、网线不小心被老鼠当饭吃了似乎也是常事儿,如果不设计好小爱的身躯,恐怕小爱时时刻刻都在断胳膊断腿。
人生病了很难快速治愈,一个重要的原因是人身上的器官只有一套,别无多余,只有把生病的器官养好才能恢复健康,而且受限于生物细胞本身的生长机制,恢复的速度太别慢。为了打破人类的局限,我们赋予了小爱三头六臂、千手千脚。具体表现之一就是小爱的每个器官(程序模块)在全国不同的机房都放多套,核心机房间的专线都做主备,这样在出了问题后可以快速更换备用资源,让小爱能快速的恢复健康对外服务,工程师(SRE运维和后端开发)负责维系更换的方法也就是预案。
再发展下去,发现备用资源需要工程师手动切换也有弊端,一来还是太慢,二来浪费资源(冷备),因此我们对小爱进行再次改造,其中一种方法是模块做成以机器为单位的集群,每台机器的健康状况集中注册存储管理,以备调用时查询,模块间要通信时,先看一下对方模块有多少健康的机器,拿到健康的机器列表后再把请求发过去,一旦有机器坏了,立马从健康列表剔除,达到不影响服务的目的,当然还有很多其他的方法,最终要达到的目的是把小爱使用的机器、机房相互做到热备,机器、机房级别的问题可以自动修复。
2、让小爱懂得断臂求生(解偶、降级)
有了三头六臂然而还是不够的,例如有时候我们发现小爱的一根手指坏了,短时间无法修复,但身体其他器官都是健康的,按理小爱只是无法提供这根手指的服务,但在设计上由于小爱对这根手指采用完全依赖等待的机制,大量请求过来,不一会儿就传导到胳膊无法工作,进而躯干无法工作最终到小爱的脑死亡,造成了整个系统挂掉(雪崩)无法服务。
所以我们要对小爱的器官(模块)分成要命的和不要命(分级)的后再进行解耦,在设计上,当某些不是要害的模块遇到不可恢复的问题后,果断降级放弃这些模块的功能,断臂求生,让影响降到最低,使劳模小爱可以基本正常对外服务,等待坏掉的器官恢复,这种方式就是让模块之间的耦合性降到最低,进而影响降到最低,尽可能为用户服务,当然解耦的原因和方式方法还有很多,比如不同模块干活儿速度有快有慢等,这时可以用队列做解耦.........
3、严管伙食,给小爱每天体检(变更、巡检)
人只有保持良好的生活饮食习惯,坚持锻炼身体、定期做体检才会有一个好身体,避免感染重大疾病,小爱虽然是个机器人,但操作上也是一样的。
①变更
小爱目前处在快速成长期,每天都有大量的模块要迭代上线,如果控制不好代码质量,很容易把问题带到生产环境,造成故障,所以在故障前做的工作越多,流入故障中的问题就会对应越少,对于小爱,我们严格管理变更,每次有新功能,都要走单元测试、集成测试、PRE、灰度,灰度后责任工程师要持续观察服务24小时以上才能全量上线到生产环境,24小时是因为java程序full gc很多都会跑一段时间才出现。另外,我们开发了很多工具对小爱的新器官做测试、压测、校验,确保小爱的宿主——服务器每次吃到的都是健康的伙食,不闹肚子。
②巡检
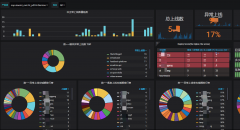
从全面质量管理的角度看,质量工作一定要做到前面,出了问题返工是最大的成本,所以我们要在生病前做更多的事情。拿人说,每年会做一次体检,预防重大疾病的发生,对于小爱同学,我们每天上下班会为她做两次体检,SRE上班第一件事儿就会查看各种自动化巡检报告,结合打开各种监控,查看小爱的健康指标是否有异常,每个指标横向对比到近24小时和近7天的变化,发现问题立刻处理,全部检查完毕后会把小爱的健康情况记录在案,形成病例档案,如遇重大问题SRE会组织各专家组进行集体会诊,商讨解决对策。
晒一下SRE基于grafna为小爱建设的一个巡检工具(导航+数据可视化分析):

4、严控小爱的饭量,决不贪食撑死(容量、熔断)
①容量
人有多大饭量吃多少饭,有多少力气干多少活儿,吃多了容易撑着闹肚子,干多了可能要累出病,机器人小爱同样如此。
这里说的小爱的饭量其实对应的是容量管理,白话说就是小爱1秒钟能干多少活,能处理多少用户的请求,对应的指标有很多,像QPS、DAU、MAU等等,对一般模块而言,SRE主要关注QPS(对于像ASR这种流式业务场景会关注尾包时延和机器GPU使用率),而且是全链路的QPS,我们根据每个模块的能力制定容量上限,通过巡检数据定期做好容量估值,提前做好扩缩容管理,一般情况下用户请求量是连续的,每天的曲线都是早晚双峰抛物线,非常规律,会有浮动但不会出现骤增骤降,如遇活动例外,比如说双十一,会由产品运营提供用户量信息,再由SRE协同开发把这些信息翻译成每个模块的QPS,然后再通过QPS计算出机器资源,提前安排扩容,保障服务的稳定性,也就是说小爱的肚子是有上限的,并不是一个无底洞,特别是GPU资源,成本很高的,所以在满足灾备的前提下,不会无限制增加资源,虽然目前通过技术能够做到弹性扩容,但实施起来还是比较谨慎的。
②熔断
凡事总有例外,比如说有一次活动运营忘记同步了,或者同步的流量和预期不符,或者干脆是没有意料到的流量,这时候就会有一波超过小爱承受能力的请求过来,消化是肯定消化不了的,如果强行吃掉可能造成整个小爱垮掉雪崩,对外完全不可使用,但如果对各模块设置容量上限,把多出来的请求在入口就熔掉放弃,这个时候有大部分用户还是可以使用的,基于此我们就制定了一个熔断规则,当QPS一旦超标,小爱立刻停吃,保住小命,绝不贪食撑死。
5、一旦生病快速发现、寻找病因,进行手术治疗(告警、定位、预案)
如果生病前的工作都都做了,但小爱还是生病了,那就想办法快速治疗吧,实践证明,想通过生病前的预防彻底去除疾病,并不现实,只是一个理想而已,总会有一些黑天鹅出现。
①告警
告警的目的是为了第一时间告诉相关工程师,小爱病了,并尽可能带有更多信息,帮助工程师判断病因使用。
在小爱,告警我们用的是小米自己的falcon,会将机器、业务指标收敛后上报falcon形成监控,再对一些核心指标加上告警,当小爱生病后会第一时间将告警发送到主要责任人,里面的学问还是很大的,如果仅仅是1个服务1个指标1台服务器1个工程师那是不存在技术和管理难点的,现实情况是成百上千个模块、成百上千台服务器、成千上万个指标、几百人的工程师团队,要把这些精确串联管理起来就是一个技术活儿了,分组、分级、依赖关系这些都必须要处理妥当,告警才不至于漏发、也不至于多发,标准化后在上下游和部署系统、oncall权限打通才能形成管理闭环。
模块数量、服务器数量、指标数量是客观存在的,而SRE不像开发只关心自己负责的模块,是要接收所有模块的告警,目前看再怎么收敛优化还是有不少短信,这个时候我们就想出了“生死告警”,对于小爱同学,绝对的生死我们从用户角度抽象了一个指标,当这个指标报出来时代表小爱真的是生命垂危,要全员关注了,反之如果这个指标没报出来,即使当前告警再多,说明小爱至少还是活着的,形象的说,“生死告警”有点像人的心跳。
②定位
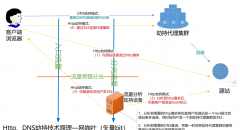
定位的目的就是寻找根因,然后对症下药。拿人做比喻,人生病了要去医院,人体的器官很多,所以在医院里分成了各个科室,哪儿病了到哪个科室去,对于小爱,在这有个技术活儿,就是成百上千的服务再加上机房的维度,怎么判断是哪个机房的哪个模块出问题了呢?怎么自上而下的快速定位故障,确定故障模块,故障机房,然后对应评估故障影响?
做过SRE的都知道,故障时的告警是一片片的,很多告警是干扰信息,是被影响的,是标不是本,混杂到告警信息里很难快速排查哪个模块出了问题,只有刚开始的那几条告警能说明真正问题,但又藏的很深,为了彻底解决这个问题,SRE开发了AiFault—小爱运维中台,在这个系统上把小爱的骨干架构画了出来,动态更新各模块的健康信息,模块实在太多无法全部展示,我们就对同类模块动态取top,模块异常时进行异常标色,真正解决了故障自上而下定位这个痛点,可以给一张有码的图如下,鼠标点击悬浮都会有更多的信息,每个模块展示可用性、QPS、时延3个指标,如触发告警异常标色的同时显示故障持续时间,底层数据源用的是我米的falcon:

③预案
预案的目标是快速止损,相当于对小爱的常见病维护了一个知识库,每一种病对应有一个药方,这个药方一般由SRE和后端架构开发共同研制,大多数是针对急诊,当病因确定后,一般情况由SRE进行预案的执行,先快速恢复线上业务,让小爱可以正常服务,然后研发再深入调查问题原因,从根本上解决问题,运维的四把斧相信做SRE的都知道——重启、回滚、切流、扩容,问题解决前很大部分的短暂恢复离不开这四把斧,重启大法在程序界真是个很神奇的东西。
6、某些器官给予小爱自愈能力(自愈)
人类的器官是有一定自愈能力的,但一般比较慢,其实作为机器人也是极其需要有这种能力,而且是快速自愈,每次要靠工程师手动执行预案,耗时太长,也就是说把经验和操作用代码实现,固化到系统上,如遇到问题不仅仅停留到告警的阶段,而是可以上升到自动操作。
我们旁路做了一个叫watcher的工具,目前处于第一阶段,可以预判full gc抓取故障现场(一般dump线程和内存信息),同时可以收集各种指标,然后根据一定的条件做出操作,解决了一些简单的故障自愈问题,目前正在从watcher到watcher-plus真正的故障自愈尝试,做这个事儿关键在建模,先做服务分类,然后同类形成故障判断模型、故障操作模型,抽象好后通过watcher-plus实现模型的运行并上报到aifault小爱运维中台记录,SRE通过对剧本的配置,把服务、故障判断模型、故障操作模型关联起来,服务做好后长期跑到要守护的服务器上,其中故障判断模型、操作模型一定要准,在建模上会结合机器指标、业务指标、再加上时间维度共同形成一个模型,然后通过实践反复认证修改。
7、生病过后,组织专家复盘,研制药方(复盘)
要复盘的一般不是小问题,而是已经对用户造成了影响,需要总结经验教训形成组织过程资产的,一般由研发、网络、DBA、SRE等多方专家对故障反复探讨后,会形成一份改进措施,内容围绕:一是根除问题避免此类问题再次发生,二是如果不能根除的,一旦发生能够快速告警,三是制定告警后有可以快速执行的预案。也就是说经过讨论后,会形成一份药房,最理想的情况是根除,不理想的情况是中医调理,还是有再次发病的可能。

 |
社长"矢量比特",曾就职中软、新浪,现任职小米,致力于DevOps运维体系的探索和运维技术的研究实践. |