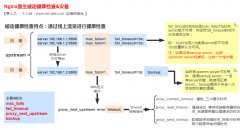
Nginx有两套日志,一套access.log一套error.log,access.log是可以用户自定义,两套日志处理好,业务的质量就了然于心了,另外,日志关键指标可视化分析我认为是运维中最重要的事情了,没有之一
Nginx有两套日志,一套access.log一套error.log,access.log用户可以自定义,两套日志处理好,业务的质量就了然于心了,另外,日志关键指标可视化分析我认为是运维中最重要的事情了,没有之一。
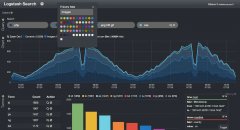
对于后期的可视化监控,核心观点两个字“收敛”,工具用grafana,把最有用的关键指标放到dashboard上,我线上设计的一个版面如下,由于日志量大,200 ok的日志基本不看,所以结合filebeat只收集了一套异常日志,异常日志定义为状态码非200或者响应时间大于0.5秒,里面要考虑几个点:
1、要用日志时间建es索引,便于分析排障;
2、数据字段要转化为数据类型,便于计算;
3、Dashbord考虑质量、性能、错误3个维度内容;
4、为了方便聚合分析,url要把问号前的接口拆出来,比如/v1/feedback/check_regid_valid?regId=DmuZXBoN4nRulcjmZczGw1fZLya151h7%2BtY0%2FgoM6qwllq%2BR723oL8fK9Wahdxee&packageName=com.tencent.news&appId=2882303761517336368,拆成/v1/feedback/check_regid_valid,后面一堆参数可处理可不处理,后面会写一下如果处理可以继续拆一下k/v;
5、grafana要动态可选业务类型、机房、机器、响应时间等信息,便于钻取分析。

对于access.log
原始日志如下(我用上撇做的分隔)
#access.log 10.132.10.29`api.xmpush.xiaomi.com`103.107.217.171`-`14/May/2019:00:00:01 +0800`/v1/feedback/check_regid_valid?regId=46quGCb9wT89VV2XzUW89bORMmralBlKriPnZbeAmIzF2nABHj LJKCI8%2FF0InyHR&packageName=com.smile.gifmaker&appId=2880376151713534`325`332`0.009`200`10.132.50.2:9085`-`0.009`GET`okhttp/3.12.1`200`lT666Qlxdq6G6iUqt/G3FrQ==
logstash清洗规则如下
filter {
ruby {
init => "@kname = ['server_addr','domain','remote_addr','http_x_forwarded_for','time_local','request_uri','request_length','bytes_sent','request_time','status','upstream_addr','upstream_cache_status','upstream_response_time','request_method','http_user_agent','upstream_status','key']"
code => "event.append(Hash[@kname.zip(event['message'].split('`'))])"
}
#将api接口拆开
if [request_uri] {
grok {
match => ["request_uri","%{DATA:api}(\?%{DATA:args})?$"]
}
}
#用日志时间建立索引,把无用字段去掉
date {
match => ["time_local", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
remove_field => ["time_local","message","path","offset","prospector","[fields][ttopic]","[beat][version]","[beat][name]"]
}
#把类型从字符型转为数字型
mutate {
convert => [
"request_length" , "integer",
"status" , "integer",
"upstream_response_time" , "float",
"request_time" , "float",
"bytes_sent" , "integer" ]
}
}
output {
#再次判断一下只收集处理异常日志
if [status] != 200 or [request_time] > 1 {
elasticsearch {
hosts => ["1.1.1.1:9220","2.2.2.2:9220","3.3.3.3:9220"]
#workers => 4
index => "logstash-im-push-mt-nginx-access-%{+YYYY.MM.dd.hh}"
}
}
#某几台机器收集全量日志,用于抽样整体情况了解
else if [beat][hostname] == 'c4-hostname01.bj' or [beat][hostname] == 'c4-hostname02.bj' {
elasticsearch {
hosts => ["1.1.1.1:9220","2.2.2.2:9220","3.3.3.3:9220"]
#workers => 4
index => "logstash-im-push-mt-nginx-access-%{+YYYY.MM.dd.hh}"
}
}
#stdout { codec => rubydebug }
}清洗后的一个截图如下,满足需求

对于error.log
原始日志如下
#error.log 有很多种,这里只写一条,后面正则会做全部匹配 2019/05/14 10:28:16 [error] 13655#0: *3199 connect() failed (111: Connection refused) while connecting to upstream, client: 47.111.97.155, server: api.xmpush.xiaomi.co m, request: "POST /v2/message/regid HTTP/1.1", upstream: "http://10.132.28.28:9085/v2/message/regid", host: "api.xmpush.xiaomi.com"
logstash清洗规则如下
#根据error日志的规律,两个正则覆盖所有情况,正则忘记从哪个大神那取的经了,多谢,另外,为了防止特殊情况出现,我保留了原始msg
filter {
grok {
match => [
"message", "(?<time>\d{4}/\d{2}/\d{2}\s{1,}\d{2}:\d{2}:\d{2})\s{1,}\[%{DATA:err_severity}\]\s{1,}(%{NUMBER:pid:int}#%{NUMBER}:\s{1,}\*%{NUMBER}|\*%{NUMBER}) %{DATA:err_message}(?:,\s{1,}client:\s{1,}(?<client_ip>%{IP}|%{HOSTNAME}))(?:,\s{1,}server:\s{1,}%{IPORHOST:server})(?:, request: %{QS:request})?(?:, host: %{QS:host})?(?:, referrer: \"%{URI:referrer})?",
"message", "(?<time>\d{4}/\d{2}/\d{2}\s{1,}\d{2}:\d{2}:\d{2})\s{1,}\[%{DATA:err_severity}\]\s{1,}%{GREEDYDATA:err_message}"]
}
date{
match=>["time","yyyy/MM/dd HH:mm:ss"]
target=>"@timestamp"
remove_field => ["time_local","time","path","offset","prospector","[fields][ttopic]","[beat][version]","[beat][name]"]
}
}清洗后的截图如下

延伸配置
对于拆出来的args,如果业务上有需要分析的信息,要继续将k/v分开,比如a=111&b=2222,拆到es里a作为key数字作为value,可以在logstash里编写如下配置
if [args] {
#很多url是经过decode过的,乱码不便于阅读,我们把它恢复
urldecode {
field => "args"
}
#以&为分隔符,将args的k/v分开
kv {
source => "args"
field_split => "&"
}
}好了,希望能在这个基础上,帮助你搭建自己的nginx可视化监控。

 |
社长"矢量比特",曾就职中软、新浪,现任职小米,致力于DevOps运维体系的探索和运维技术的研究实践. |