这是最近做的一次优化,以一个小方案的形式分享一下优化过程。 一、业务简介 Resolver又叫httpdns,是消息系统以http形式提供域名解析的服务,用户在连接到消息系统时,先通过resolv
这是最近做的一次优化,以一个小方案的形式分享一下优化过程。
一、业务简介
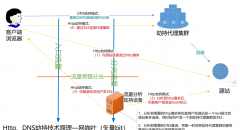
公司内部叫Resolver服务,其本质是一个httpdns系统,以http形式提供域名解析的服务,用户在连接业务时,先通过resolver服务获取ip地址列表,然后通过拿到的ip列表连接到对应服务器上,解决了域名劫持和连接降级的问题。
Resolver服务采用nginx+后端的系统结构,后端是开发同学用c++自写,前后端通过fastcgi协议进行通信,平时单机的QPS在7k左右,高峰期达到1万以上。
二、遇到问题
业务到高峰期QPS达到1万以上,服务出现大量502特别是鲁谷机房,进而拒绝服务,业务瞬间基本属于不可用的状态,尝试通过nginx的limit来限制解决,效果不是很好,大量用户被切掉,存量用户还是有很多的502,所以只有扩容和想办法优化两条路可走。
三、分析问题
Nginx本身是一种非堵塞的模型,1万级别的QPS对于nginx本身的压力很小,分析后发现request_time大的原因在于upstream_response_time大,那就是说后端c++的慢了,所以怀疑是后端到达了业务瓶颈,与开发同学分析日志后确定了这个结论,开发同学第一时间提出了加机器的要求。
作为运维,继续分析是否可以通过运维手段做一些优化,此服务的本质是用户端发起一个http请求,然后服务返回一个ip地址列表,这个列表会根据不同的url参数有所变化,但同一个参数在1分钟内变化的可能性基本没有,进而与开发确认业务逻辑,在业务处理上没有依赖ua、reffer、cookie等额外参数判断,开发的同学表示这个解决缓存1分钟时绝对没有问题的。
四、解决问题
好了,分析到现在有个方向性的模糊思路了,那就是是否可以用nginx cache呢,这个是非常熟悉的领域,再结合内存的使用,按照之前的业务经验看,依照命中率的不同可以起到非常好的优化效果,性能可能会飞起来,哪怕命中率小,命中一个同样赚了一个,好了马上行动起来做测试。
查看nginx配置文件,首先遇到的问题是前后端不是用proxy_pass与upstream通信的,这就意味着最常使用的proxy_cache直接用是行不通的,而之前用的最多最成熟的就是这个,继而想通过加一个多端口的server来引入proxy_pass,这个也是之前常用的方案,这么做的坏处是增加nginx的复杂程度,不得已只能这么做,可以作为一个打底方案。继续分析,fastcgi通信其实是有一个fastcgi-cache的,虽然很少用,但是可以测一下。
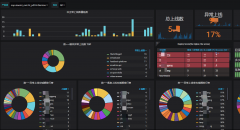
调研机器的内存使用情况,拿出5G的内存做缓存用是绝对没问题的,而且1分钟的内容可能也泡不到5G,起码资源是够的,然后翻google和百度,查找各参数的配置含义,进行配置,反复测试最后形成一份可用的配置,将缓存数据放到了/dev/shm,然后进行灰度,效果非常明显,基本单机的容量按照后端算可以提升5倍,晒一下几张图:



对应服务器内存的消耗,也确认了很小的想法,如下:

五、优化效果
通过不到200M内存的服务器资源消耗,达到了命中率75%到80%的效果,机器的性能可以提升到5倍以上,这次优化主要达到了如下效果
1、节约了服务器资源,后端穿透量降为1/5,容量提升5倍,节约了大量服务器;
2、减缓了后端c++的压力,每台服务器后端的请求书基本降为原来的1/5;
3、起到了消峰作用,高峰期后端的请求量不会抖动,不会有压力;
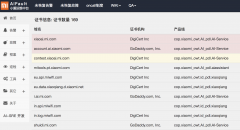
4、对于错误5xx的降级,一旦后端出错后,nginx会返回最近一次缓存的结果吐给用户,用户依然可以拿到解析列表,截图如下。



 |
社长"矢量比特",曾就职中软、新浪,现任职小米,致力于DevOps运维体系的探索和运维技术的研究实践. |