不管什么业务,吞吐量的本质是木桶原理,能跑多大量取决于木桶最短那个板(脑袋里是不立刻出现了木桶模型,哈哈)!!换句话说,当有能力提高短板的高度时,业务的吞吐量就会上升,但

瓶颈分析是应用运维老生常谈的一个事儿,经常做,今天总结一下,希望对你有所帮助。
不管什么业务,吞吐量的本质是木桶原理,能跑多大量取决于木桶最短那个板(脑袋里是不立刻出现了木桶模型,哈哈)!!换句话说,当有能力提高短板的高度时,业务的吞吐量就会上升,但同样有个边际效应,经过多次的优化后,当再次提高短板的成本非常非常大,而提高的量却很低时,那就不要较劲了,直接加服务器吧。

言归正传,先讲一下QPS跑不上去的现象,表现就是高过一个点后错误率增加、响应时间变长、用户体验变差,带来的副作用就是用户的流失,很显然是遇到瓶颈了,那么瓶颈在哪儿,我们怎么分析呢?
开发二话不说要求加服务器,作为应用运维不过脑子直接向老板要么?服务器或许已经够多了,用户总量你心中知道没有多少,用户增量也没多少,但业务上对服务器的需求却像无底洞一样,需要不停的扩容再扩容,其实这个时候就该静下心来分析一下了,到底是什么原因导致吞吐量跑不上去?负责任的说,运维给公司省钱就是给公司挣钱了,抓到点上这个数字还特别的可观,总结后,一般瓶颈问题从下面三个维度来分析。
一、机器本身
分析的整体方法是由浅入深、层层深入,先看服务器本身的指标有没有遇到短板,这个层面的分析也是相对最容易的,在配置层面(ulimit相关例如fd等)检查没有问题后,从下面四个方面进行分析。
1、cpu
cpu粗面上看有两个指标,当前使用率和负载,使用率反应的是当前cpu使用的情况,而负载反应的是cpu任务的队列情况,也就是说任务排队情况。一般cpu使用率在70%以下,负载在0.7*核心数以下,cpu的指标就算正常。
也有例外情况得分析cpu的详细指标,在运维小米消息系统的一个模块时,服务器用的是阿里云的ecs,整体cpu利用率不到30%,但业务就是跑不上量,和肖坤同学查后发现cpu0的软中断极高,单核经常打到100%,继续查后发现网络中断都在cpu0上无法自动负载,和阿里云工程师确认后是所在机型不支持网卡多队列造成的,最终定位cpu的单核瓶颈造成了业务整体瓶颈,如下图:

cpu用满的解决办法简单粗暴,在程序无bug的前提下,换机型加机器,cpu本身没单独加过。
附一篇排查cpu问题的博文:4核服务器cpu使用率10%负载飙到23.5故障排查
2、内存
内存常规看的是使用率。这个在做cdn的小文件缓存时遇到过,当时用的是ats,发现程序经常重启,业务跟着抖动,查日志后发现系统OOM了,当内存快要被占满的时候,kernel直接把ats的进程给杀掉,然后报out of socket memory,留的截图如下:

同样,在应用层没有优化空间时,那就加内存吧!!
3、IO
IO主要指硬盘,一般用iostat -kdx 1看各种指标,当 %util超过50%,且偶发到100%,这说明磁盘肯定是到瓶颈了。
要进一步查看是否由于IO问题造成了系统堵塞可以用vmstat 1 查看,下图b对应因IO而block的进程数量。

这个在新浪做图片业务时遇到过,是一个源站的裁图业务,设计上为了避免重复裁图,在本地硬盘上存了一份近7天的数据,由于用python写的,没有像JVM那种内存管理机制,所有的IO都在硬盘上。有一天业务突然挂了,和开发查了2个多小时未果,中间调整了各种参数,紧急扩容了两台机器依然不起作用,服务的IO高我们是知道的,查看IO数据和历史差不多,就没往那方面深考虑,后邀请经验颇多的徐焱同学参与排查,当机立断将IO处理逻辑由硬盘迁到内存上,IO立马下来了,服务恢复。
IO问题也得综合的解决,一般从程序逻辑到服务器都要改造,程序上把重IO的逻辑放在内存,服务器上加SSD吧。
4、网络
网络主要是看出、入口流量,要做好监控,当网卡流量跑平了,那么业务就出问题了。
同样在运维图片业务时遇到过网卡跑满的情况,是一个图片(小文件)的源站业务,突然就开始各种5XX告警,查后5XX并无规律,继而查网卡发现出口流量跑满了,继续分析,虽然网卡是千兆的,但按理就cdn的几个二级回源点回源,不至于跑满,将文件大小拿出来分析后,发现开发的同学为了省事儿,将带有随机数几十M的apk升级包放这里了,真是坑!!
网卡的解决方式很多,做bond和换万兆网卡(交换机要支持),当前的情况我们后来改了业务逻辑,大于多少M时强制走大文件服务。
二、程序代码
当查了cpu、内存、IO、网络都没什么问题,就可以和开发好好掰扯掰扯了,为什么服务器本身没什么压力,量却跑不上去,不要以为开发写的程序都很优良,人无完人何况是人写出来的程序呢?很多时候就是程序或技术架构本身的问题跑不上去量,这个过程运维还是要协助开发分析代码逻辑的,是不是程序cpu和内存使用的不合理,是不是可以跑一下多实例,把某些逻辑比较重的地方做下埋点日志,把执行的全过程apm数据跑出来进行分析,等等。
一个典型用运维手段解决代码瓶颈的案例详见博文:记一次HttpDns业务调优——fastcgi-cache性能提升5倍
三、逻辑架构
发展至今,微服务架构设计已成为大型互联网应用的标配,各模块间通过HTTP、RPC等相互依赖调用,如果查完服务器、程序依然没有问题,再往深处走就得协同开发分析逻辑架构了,这也是微服务系统下的一个特色,不是因为服务器或者程序bug造成了业务瓶颈,而是某个模块的短板造成了整个业务吞吐量上不去,这个很好理解,甚至有很多接口用的是公网公共服务。
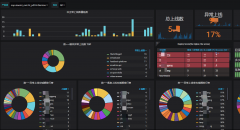
具体分析上,从一次完整请求的角度,从头到尾理一遍外部依赖的上下游资源和调用关系,外部资源包括api接口、DB、队列等,然后在每个点做埋点日志,将数据进行分析,我们在线上用这种方法不知道分析出了多少瓶颈,如果程序没有做很好的降级熔断,由于程序本身的执行是堵塞的,一个接口慢影响到整个请求,进而QPS上来后请求变慢错误数增高的例子很多,在这种情况下,如果瓶颈的接口是别的部门或公网资源,加多少服务器都解决不了问题,进行改造吧,下图是运维门户业务时做的依赖接口超时监控,性能差的接口一目了然:

好了,写到这,希望对遇到问题不知如何下手的你有所帮助!!

 |
社长"矢量比特",曾就职中软、新浪,现任职小米,致力于DevOps运维体系的探索和运维技术的研究实践. |