作为一名互联网应用运维,对什么是好的产品(技术架构角度)有自己的感悟(我负责运维的产品高峰日访问量在10个亿,机器分布在全国不同机房,虽也有大小问题,但整体运行不错)。产品
作为一名互联网应用运维,对什么是好的产品(技术架构角度)有自己的感悟(我负责运维的产品高峰日访问量在10个亿,机器分布在全国不同机房,虽也有大小问题,但整体运行不错)。产品运维是一个既要和开发又要和各基础运维打交道的职务,要考虑到结构、扩容、容灾、高可用和优化等各方面的事宜,又要研究产品的逻辑本身(排障时需要),工作中发现,一个好的互联网产品不仅在优秀的代码本身,更体现在后期的易运维性、可扩展性、高可用性等。随着用户量的变化、机房的变化甚至员工的离职,可能随时需要弹性的调整资源改变策略来应对各种问题,而这就是体现产品是否足够优秀的时候。
如果是新产品,在设计阶段运维就有必要参与进来了,因为做出来的产品最终都要交付上线,放到服务器上给用户提供服务,一是运维更加了解线上环境,研发阶段简易的demo开发环境放到线上会遇到各种问题;二是开发过程如果缺少运维意识,上线后在做资源弹性调整及其它策略改变可能会遇到各种麻烦;另外运维人员会根据模块属于不同的IO消耗型、cpu消耗型、内存消耗型等需求提出更加合理的上线服务器环境,提前参与产品中也可对节省成本的同时提高性能有很大帮助。根据经验,我总结了4个要素,同样如果对于已经做好的产品,从优化的角度去提升产品性能同时减少故障,也是从这“4要素”出发:

一、整个系统的功能要模块化(微服务),单个模块高内聚低耦合;
大型互联网应用面对全国乃至世界范围的使用,要面对开发分工、迭代、扩容等各种场景,使用中要保证优秀的用户体验、良性的迭代升级和业务扩展,一定要使用微服务的架构设计思想进行模块拆分,一个没有模块划分的系统是不可能完成这项任务的,想想几百号人围绕着一套代码转是个什么样子。一个优秀的大型互联网应用会在设计之初就进行模块化,每个模块各司其职,模块间通过HTTP
API或者消息队列进行通信,各模块根据工作量和难度分给不同项目组负责,最后单个模块形成高内聚、模块之间形成低耦合的模型,该是谁的事儿就找谁,当然功能模块怎么划分更加科学,就需要做研讨了,研讨中要从当前开发的科学性和后期上线可运维性两个维度来做考虑。
二、每个功能模块相对独立易部署、所需资源弹性可扩展;
要应对线上变化的环境、用户量的自然及突发性增长、开发者的人员变动,每个功能模块在做到功能独立高内聚的同时,要做到运维的可交付、资源的可弹性扩展。
运维的可交付体现在模块的易部署(越简单越好),部署过程不依赖修改源代码,所需的配置文件、代码可以做到统一下发。
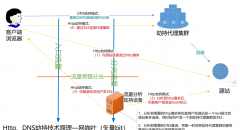
资源的弹性扩展是为了应对用户量的自然及突发性增长,比如说要做一个活动,访问量会突发翻倍,这时模块要能做到易扩展,可以弹性的通过简单的扩容服务器来增加系统吞吐量,不至于造成系统瓶颈,每个模块做到了弹性可扩展,整个应用才会变成一个弹性可伸缩的强大产品。
三、每个功能模块无单点故障点,如遇后端依赖故障可以降级服务;
为了让开发和运维人员能够睡个好觉,一个好产品的每个模块必须能够做到服务器间容灾且无单点故障,就是说一台服务器挂了不会影响到模块服务,进而影响到整个应用的瘫痪,每台服务器模块都是一个独立的个体,互不影响,当某台服务器挂了之后剩余的服务器能把活儿接起来,当然这是最理想的模型,如果实在无法做到热备,最起码得做到无需人工干预的冷备。
模块之间都是协同工作的,每个模块都可能承上启下相互依赖,在向前端输出任务处理结果时也依赖后端其它模块的处理结果,这时就要考虑到万一依赖的后端模块挂了或者超时怎么办的情况,以防出现雪崩的连锁反应,这时模块就有必要设置降级预案机制,比如说当那不到结果或为空时向前端返回一个默认的或最近处理的结果,应付一下用户,总比返回错误信息要强,然后腾出时间解决问题,再比如是个新闻类应用,可以返回一个近期的静态页面。
四、每个模块的日志健全,做到可分析、可监控。
日志的健全性很重要,日志可以及时的发现问题、分析问题、分析模块的性能、故障点等等,总之日志可以反应出各种问题,其包含但不限于操作系统日志、业务日志(访问、超时、错误)、后端资源依赖日志等,分析的结果同时正向反馈到下一步的产品迭代研发中去。
对于监控,也分为了基础监控、应用软件监控、业务监控、依赖监控四个层面,简单介绍一下,基础监控指服务器各种基本指标包含cpu、负载、io、内存使用、网卡流量等的监控,应用软件只nginx、tomcat、php-fpm等应用软件本身性能的监控,业务监控是指访问后或对于任务处理情况的日志监控,比如说nginx的访问日志,依赖监控是指其依赖模块或资源的监控,比如说MC、redis等。
写在最后:如果一个大型互联网应用能够做到这“4要素”,这个产品就是一个很高级的妖怪了,能够抵抗狂风暴雨。(所说“产品”是技术层面产品,并不是为网民设计的接入层用户体验类逻辑产品)
“运维网咖社”原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 、作者信息和本声明。否则将追究法律责任。http://www.net-add.com

 |
社长"矢量比特",曾就职中软、新浪,现任职小米,致力于DevOps运维体系的探索和运维技术的研究实践. |