前记: 所谓干一行爱一行,人生处处是《围城》这是人性,但在改变那一刻之前,自应全心全意研究本行,全心投入,不计回报,用心在当下,写到体系就像是前面所有博客的一个帽子
前记:所谓干一行爱一行,人生处处是《围城》这是人性,但在改变那一刻之前,自应全心全意研究本行,全心投入,不计回报,用心在当下,写到体系就像是前面所有博客的一个帽子,现在把他总结整理出来,希望对你有所启迪。
自动化运维体系是一步步发展过来的,构造自动化运维体系的前提得先了解原始运维体系,原始运维体系好比是本,有了本才知道怎么实现自动化、实现Aiops.......
首先,运维有其业务职能,全部职能梳理规范后形成章程、纲领和体系,互联网最大的特点是“快”和“变”,但不代表没有固定的体系,恰巧有的是应对"快"和"变"的体系,从事一线运维这些年,体会到千象背后是有恒道的,所谓万变不离其宗,运维工作一切围绕高SLA和低成本为目标运转,只是工具在围绕运维体系变来变去而已,从开发的角度理解运维体系就像是算法,实现算法的语言和方式就像是工具,自动化就是工具的升级。
在前期,运维人员在和各部门无数的磨合、探索中慢慢形成了工作体系,也就是运维体系,此体系无形的规范了运维的工作,以及工作该怎么干,运维人员通过这个无形的纲领开展日常工作并保障业务的健康发展,这个阶段可以说是制度为王、制度规范,没有系统的自动化运维平台,有的只是零散的一些大小工具,各种事物基本靠人工、靠制度、靠约束,虽是原始阶段,但也是运维最真实的样子,忙碌而又忙碌,效率总跟不上需求,制度总跟不上执行,与开发的协作总难同一频道,需要大量的运维人力。
再向后发展,为了提高效率的同时解决与开发间的沟通协作问题,提出了DevOps,大家开始做自动化,这个自动化其本质是把运维体系落在一个到多个系统上,通过自动化系统来提高工作效率,同时用系统来实现制度,开发和运维都在一个系统上协作,遵守同样的规则,协作上也高效多了,这个阶段到了技术为王、平台规范,市场上出现了运维开发,出现了SRE,各种问题得到了有效的解决,当然解决的程度取决自动化系统做的优劣,这个就参差不齐了,但出现了这个发展方向。
再向后发展,出现了AiOps......
个人感觉,有两个维度变化很明显,越来越注重技术解决问题,人员需要越来越少,能用技术工具替代的岗位在慢慢被替代,随着自动化平台的成熟稳定,理论上理想的终极状态可能只留"运维平台+应用运维",其他运维转岗应用运维,应用运维转岗技术运营。
那么如果你恰好接到一个从零开始建设的运维工作,怎么有序规划、快速迭代到自动化运维体系呢?下面我们分两步把他拆开看一看。
一、 规范工作,形成运维服务体系(制度为王)
1、变更规范
- 上线变更:代码上线、扩容;
- 配置变更:系统配置、应用配置;
- 网络变更:网络割接、设备更换;
- 其它变更:流量调度、服务切换、服务下线...
- 原则:a、制定变更审核流程;
b、制定变更相关方通知(群、邮件);
c、制定变更回滚策略;
d、遵循测试、单机灰度、机房灰度、全量上线的规则;
e、下线变更要将服务器依赖处理干净,比如说挂着vip、有域名解析。
2、容灾规范
- 服务灾备:多机器、多机房;
- 数据灾备:多备份、异地备份;
- 网络灾备:多线路、多设备;
- 原则:a、自动切换 > 手动切换;
b、无状态 > 有状态;
c、热备 > 冷备;
d、多机房 > 单机房。
3、容量规范
- 系统容量:木桶原理计算系统的上、下行容量、用量、余量;
- 模块容量:模块的上、下行容量、用量、余量;
- 机房容量:分机房的容量、用量、余量;
- 单机容量:压测单机的容量,一般用于反向计算机房、模块容量;
- 原则:a、制定模块单机容量指标,并记录文档(比如QPS、连接数、在线用户数等),
b、容量要考虑下行(读)、上行(写),考虑存储增量;
c、计算当前模块总容量,收集当前的用量,并对比容量计算余量;
d、系统总容量可以根据木桶原理,找到短板模块后,反向计算出来。
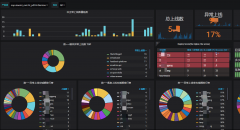
4、巡检规范
- 系统核心指标DashBoard;
- 分模块核心指标DashBoard;
- 基础资源核心指标DashBoard:服务器;
- 依赖资源核心指标DashBorad:依赖db、依赖接口;
- 自动化巡检报告;
- 值班oncall安排;
- 原则:a、DashBoard核心在于收敛、舍得;
b、自动化巡检的必要性在于异常侦测,预防故障,是事前的。
5、告警规范
- 基础监控:CPU、内存、网络、IO;
- 应用监控:进程、端口;
- 业务监控:日志、业务埋点;
- 依赖监控:数据库、依赖接口...
- 原则:a、核心监控收敛成告警,并对告警进行分级,备注告警影响;
b、核心监控形成可排查问题的DashBoard;
c、告警的价值在于实时发现故障,是事中和事后的。
6、预案规范
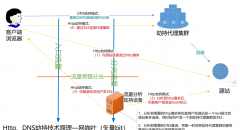
- 线路切换:移动、电信、联通、BGP等多线路切换;
- 机房切换:不同机房切换;
- 机器切换:不同机器切换、故障机器自动摘掉;
- 服务降级:无法切换时,如何降低标准继续服务;
- 数据库切换:主从切换、读写切换;
- 网络切换:主备线路切换、链路切换;
- 原则:a、域名切换 > 更换IP;
b、自动摘掉 > 手动操作;
c、自动切换 > 手动切换;
d、考虑好雪崩事宜。
7、故障管理规范
- 服务分级,确定各服务用户角度的影响;
- 制定分级后各服务SLA,制定问题、故障分级标准;
- 制定故障通知、处理规范;
- 制定故障复盘,改进措施按时保量完成的规范;
- 原则:a、拥抱故障,但同一故障解决后,不应重复出现。
8、权限安全规范
- 开发、运维、临时权限;
- 安全上符合安全审计标准。
9、文档、工具规范
- 统一共享知识文档;
- 统一共享各种脚本工具;
- 原则:a、理想的情况是“一站式运维平台”,一个平台涵盖所有工具操作。
10、标准化规范:
- 主机名标准化;
- 应用软件安装结构标准化;
- 日志存储标准化;
- 日志格式标准化;
- 域名使用标准化;
- 原则:a、主机名尽量能看出更多信息,比如服务、模块、机房等;
b、日志是排查问题的重要信息,一定要标准化,方便手工排查,更是为了以后用工具处理打下基础。
11、资源管理规范
- 服务器
- vip
- 域名
- 证书
- 代码
- 原则:a、资源之间是有关系的,要建立有关系的资源管理。
二、 技术实现制度,搭平台,建设自动化运维体系(技术为王)
有了第一阶段的运维体系为基础,就可以考虑用平台工具来实现零散的手工操作、制度规范,理想的情况是“一站式运维平台”解决所有事情,平台后端集成使用开源技术方案作为支撑,对于用户优雅而统一,目前开源项目中尚未找到很好的“一站式运维”产品,下面罗列一下常用的解决某类问题的技术方案。
1、监控告警方案
- Zabbix:https://www.zabbix.com
- OpenFlcon:https://github.com/open-falcon/falcon-plus
- Prometheus:https://prometheus.io
- Grafana:https://grafana.com
2、日志分析方案
- ELKB:https://www.elastic.co
3、安全堡垒机方案
- JumpServer:http://www.jumpserver.org
4、持续集成部署CI/CD方案
- Jenkins:https://jenkins.io
- GitLab:https://about.gitlab.com
5、容器技术方案
- Kubernetes:https://kubernetes.io
6、配管自动化方案
- Puppet:https://puppet.com
- Saltstack:https://www.saltstack.com
- Ansible:https://www.ansible.com
8、一些运管集成方案
- SaltShaker:https://github.com/yueyongyue/saltshaker_api
- 腾讯蓝鲸:https://github.com/Tencent/bk-cmdb
- OpsManage:https://github.com/welliamcao/OpsManage
......
从制度到技术的进化就是效率提升、成本降低的过程,也是培养用技术工程思想解决问题的过程,自动化做的越好,所需要的人力反而越少,解决各种问题的效率也越高,现在市场上解决单个点的方案如上罗列有很多,但从用户的角度看就像“五行有了缺一个串”,做一个事儿打开一个系统实在太痛苦了,好一点的大厂做个单点登录,解决了一系统一账户的问题,不过也是一堆系统,用户体验差。即便如此,为了“一站式运维”的方向,很多企业都会量身开发一套个性化的运维管理系统,将资源、流程、事物、审核、自动化.....尽量封装到一个平台上,提高运维操作效率,相信将来会更方便、智能。
至于最近热炒的AiOps,更多的也是为了提升效率、降低成本、降低操作出错,让运维更加智能化、无人化,作为一线运维,从实际情况看,可能只适合部分场景,有些操作、判断还是离不开人。

 |
社长"矢量比特",曾就职中软、新浪,现任职小米,致力于DevOps运维体系的探索和运维技术的研究实践. |