一个大型的互联网应用,意味着大用户量、业务模块多、服务器多、各种资源占用多,在拿到一个大型的互联网应用,运维保障工作应该从哪些方面抓起呢? 首先还是看运维的目标,追
前记:用了很长时间的昵称“愚人乙”决定换掉,换一个有科技感有力量的昵称“矢量比特”,“矢量比特”即是有大小、方向、作用点的字节。
一个大型的互联网系统,意味着大用户量、业务模块多、服务器多、各种资源占用多,在拿到一个大型的互联网应用,运维保障工作应该从哪些方面抓起呢?
首先还是先看运维的目标,用最快的效率追求更高的SLA、更低的成本。所有事情都是以这个目标为出发点,SLA指更高的服务质量,落实到数据上就是线上服务的可用性和性能,可用性是3个9的时候能不能达到4个9?能不能持续保持4个9?平均响应时间是100ms的时候能不能优化到80ms?更低的成本指的是在同样的SLA下,能不能用更少的服务器、更精简的架构跑起来?所有的制度和自动化工具,都是为完成这一目标。
再看SLA和成本,两者并不是独立的,一般而言高SLA意味着高成本,例如用10台服务器跑的服务改用100台服务器跑,服务性能和质量的SLA肯定是有提升的,所以这两个指标其实是一个对立与统一的平衡,两个之间此消彼长,共同进步。当SLA和成本产生冲突时,为了服务的稳定性,我们一般的做法也是先稳住服务质量,再考虑优化成本,也可以说用成本先稳定住质量,再慢慢找出用这么多服务器、这么多资源的原因,毕竟如果服务质量没有了、用户流失了,一切都是零。
更高的SLA其实意味着更少的线上故障,如果我们以此为出发点去梳理运维的工作的全貌,其实要抓的工作阶段就变成了故障前、故障中、故障后,我们要尽量加大故障前的工作投入,减少流入故障中的问题数量,一旦流入故障中,我们要想办法快速止损,止损完在故障后做好故障复盘,形成改进措施避免同类问题再次发生,继而流转到故障前,循环往复,当这个圈的转速越来越慢时,说明质量就越来越好了.........为了更形象的理解,画了一张全面质量管理的图来展现。

上图将运维的工作从故障生的角度分成了8大块,每一块可能对应了很多个系统和制度作为支撑,全部形成了整个运维服务体系,我们日常做的工具和制度就是为了每个业务环节执行的更高效,PS 对于大型系统运维的一个关键在于各种标准化,标准化意味着批量操作意味着整齐划一,现在拆开了说一下这8块工作。
1、故障前—目标:减少问题流入“故障中”
①抓-变更
故障不是无缘无故的就生发了,很多发生在于变化,变化当中很大的一个又是迭代上线,从每年故障的历史数据看,有很大一部分故障都是由于上线变更造成的,所以要严管变更,控制好质量后再上线。
管理变更主要是控制线上的“马路杀手”,要做好单元测试、集成测试、线上灰度,然后再全量上线,保障万无一失,从成本的角度看,上线后再回滚也是成本最大的一种方式,影响了用户,然后还要重新返工。
有些变更类故障不是上线后马上能发现的,比如java程序的full gc,可能上线一天后才能发生,所以这个时候要一些制度作为辅助,比如说重大节日前几天就不允许上线了,下班时间要找老板审批后走紧急上线等等,加大非正常时间上线的变更成本,让开发和运维对线上服务慢慢培养起敬畏之心。
②抓-容量
容量的管理关乎到质量和成本,很多时候对于容量是模糊和缺失的,具体表现就是发生了容量故障、看到了cpu和内存报警了才想到扩容,公司要优化成本抓机器使用达标率才知道缩容,基本是被动的,而且没有量化数据。没有量化的容量管理就像中国厨师做饭一下,根据经验多加点盐、少加点醋,这个多和少凭的是感觉,基本是不可主动管理的,对某个人的经验依赖性很大。
再提成本,容量的管理对成本是至关重要的,有了容量数据,再结合目前的用户就知道目前的服务器数量合理不合理,有多少浪费的,又或是需要扩容了,有了容量数据也可以暴露很多性能问题,比如一台32核128G的机器才跑10个QPS,这显然是不合理和需要重点优化的。
根据实际经验,容量的指标一定要用业务指标不要用机器指标,举个例子,很多时候如果代码质量差,比如前面说的10QPS,机器的CPU、内存等跑的反而挺高的,这个时候应该扩容么?业务指标一般指像QPS、在线用户数、长链接数量等这些,理论情况下,先有了不同配置的单机容量数据,再计算出集群的容量,继而算出模块的容量,再继而算出整个产品的容量,在做容量测量用的最多的工具是压测和全链路压测,这个根据不同的情景使用。
对于容量数据首先保证有,再争取越来越准,然后根据代码、架构、机型改动情况动态更新。
③抓-灾备
灾备和成本也是相互矛盾的一对,做多机房灾备成本一定高,因为机房之间要保有相互承载用户的余量,不做多机房灾备成本肯定是要低的,但如果某个机房垮了无法服务,业务就无处可切,就真的垮了,所以我们要根据业务的级别做合理的灾备。
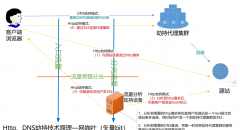
灾备意味着做冗余,合理的灾备可以保障在故障出现时,快速进行业务切换,保障用户的可用性。一般而言灾备分为热备和冷备,冷备是指准备好资源平时空放,只有故障时才用一下,造成很大的资源浪费,所以一般能做热备的就不做冷备。
做热备的方法有很多,现在很多业务都是面向服务的,最常见的热备方案其一是搭载负载均衡,通过心跳健康检查服务自动调度,其二如果是移动、联通、电信某条链路出现故障就通过域名解析进行切换。
最典型的冷备方案就是keepalived,通过vip漂移的方式对某个服务进行冷备,原理就不说了。
灾备做好了,可以大大降低故障出现时的业务压力,先把服务切了再查故障,心态要轻松很多,加之如果能够自动切换(好像可以叫故障自愈)那就更好了。
④抓-巡检
巡检的意义在于发现潜在的问题,将尚未形成故障的问题提前暴露,提前解决。在方法上,可以人工巡检也可以通过系统实现,巡检完后发送巡检报告,将一些核心指标的变化情况根据业务的属性进行标记通知。
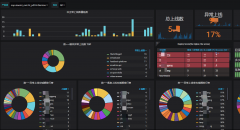
无论是手动还是系统巡检,都要对每个模块的核心指标进行梳理,形成每个模块的核心指标的鸟瞰screen,一来每天到办公室首先要巡检一下业务情况,二来在遇到故障的时候要迅速看一下各个指标的变化做故障定位。
各模块的巡检screen一般要包括QPS、错误、时延、外部依赖错误、机器指标这几个大项,便于一眼发现问题所在,快速找到根因,定位故障影响范围。
2、故障中—目标:快速发现问题、快速止损
如果前面的工作都保质保量的做了,故障依然出现,那就考虑怎么应对处理吧,故障的处理关键有3个环节。
⑤抓-告警
不说告警没配等特殊情况,告警应该是故障的第一事件,当oncall人员收到告警,判断影响后,分发给相应的同学处理,直到故障恢复。
所以在告警一定要管理好,告警要根据事件的影响程度分级,告警短信和邮件里尽可能携带更多的判断信息,做的好的甚至可以做一下故障参考预判。
告警的建设上一定要围绕3个点准、少、快,准是告警的信息准,少是告警的数量少都是收敛后的有效告警,快指的是告警的实效性高速度快。
⑥抓-定位
oncall同学收到告警简单的判断后,会把告警分发给处理人,这个时候就到了故障定位环节。
故障定位依赖于对业务架构细致的了解、依赖于线上的经验,一般会借助监控进行排查,这时候在巡检阶段建的核心指标screen就派上用场了,通过screen和核心指标基本可以做个预判,然后再通过日志分析或登录服务器查看详细日志进行根因排障。
定位也是有轻重缓急的,首先要找到故障模块和故障范围,找到后先根据预案将业务切掉再去排查原因,减少线上用户的影响。
⑦抓-预案
预案是指在定位到故障模块和故障范围后为了保障业务的稳定,及时止损所进行的操作,
为了故障发生后尽快止损减少影响,在平时要考虑好各种故障发生的肯能性,并做好预案是非常重要的,预案也分为容灾预案和降级预案,容灾预案基本无损,降级预案可能会影响一些用户体验了,但是不影响主体功能,如果什么预案都没有只能生抗了。
3、故障后—目标:消灭同类故障
⑧故障管理
故障管理是整个故障的善后工作,追责任的部分除外,那他的意义就是防止同类故障再次发生。一般会以故障复盘会的方式约所有相关方进行全过程复盘,最后形成的文档叫“故障报告”,我认为里面最重要的两个内容一个是故障原因(到底是天灾还是人祸?根因找到了没有),一个是后续的改进措施。
管理中有句话叫“再好的制度如果不执行等于没有“,在改进措施的执行上,很多好了伤疤忘了痛的做法屡见不鲜,改进措施改着改着就没了,造成了同类故障重复出现,这个过程中一定要确保形成的改进措施保质保量的完成。

 |
社长"矢量比特",曾就职中软、新浪,现任职小米,致力于DevOps运维体系的探索和运维技术的研究实践. |