业务的系统结构是nginx+php-fpm,服务器是12核cpu、16G的内存,工作中cpu、内存、io、网络利用率都不高,但QPS就是跑不上去,超过800就会有少量错误并且性能下降,push瞬间服务就会抖动。排除了依
业务的系统结构是nginx+php-fpm,服务器是12核cpu、16G的内存,工作中cpu、内存、io、网络利用率都不高,但QPS就是跑不上去,超过800就会有少量错误并且性能下降,push瞬间服务就会抖动。排除了依赖的资源mc、redis原因后,那剩下的就是nginx和php-fpm本身,继续分析,nginx用的是tengine2.1.2,之前做cache时并发连接数测到30万、QPS1.5万没出过问题,那最有可能就是php-fpm本身遇到了瓶颈了。对于php-fpm,之前将进程数从128调到了256,继续加大并不是办法,可能根本就不是进程数的问题了,后来多次思索,果断效仿tomcat多实例的方法对php-fpm做多实例,想着最大限度的利用服务器闲散的cpu、内存、io、网络,提高单台服务器的吞吐量。
对于这种模型的介绍详见之前博客:WebService之nginx+(php-fpm)结构模型剖析及优化
调整思路及步骤:
1、新建php-fpm的配置文件php-fpm2.conf
第1个实例用的9000端口,第2个实例用9001端口,修改后的配置文件(php-fpm2.conf)如下:
[global] pid = run/php-fpm9001.pid error_log = /data1/var/logs/php-fpm/error9001.log log_level = warning emergency_restart_threshold = 10 emergency_restart_interval = 1m process_control_timeout = 5s daemonize = yes [www] listen = 127.0.0.1:9001 listen.backlog = -1 listen.allowed_clients = 127.0.0.1 user = www group = www pm = static pm.max_children = 256 pm.max_requests = 1024 request_terminate_timeout = 10 request_slowlog_timeout = 5 slowlog = /data1/var/logs/php-fpm/slow9001.log rlimit_files = 65535 rlimit_core = 0 chroot = chdir = catch_workers_output = yes pm.status_path = /php_status9001
指定配置文件的启动命令如下,同步更新加入到服务管理/etc/init.d/php-fpm2。
/usr/local/php-fpm/sbin/php-fpm -y /usr/local/php-fpm/etc/php-fpm2.conf
2、启动服务查看9001端口以及进程
3、修改nginx的配置文件,增加轮训upstream
修改nginx的配置文件,增加轮训的upstream,将fastcgi_pass指向改为upstream名称,日志中添加$upstream_addr、$upstream_response_time字段便于分析问题,具体修改如下:
upstream phpcgis {
server 127.0.0.1:9000 max_fails=10 fail_timeout=5s; #在5s内出现10次错误,惩罚5s钟不使用这个server
server 127.0.0.1:9001 max_fails=10 fail_timeout=5s;
keepalive_timeout 65s;
}
fastcgi_pass phpcgis;4、用./nginx -t测试一下配置文件,将服务reload并查看日志
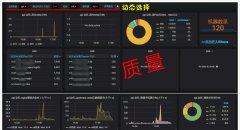
5、服务器和业务日志的各指标监控数据如下
a、nginx请求日志的平均响应时间

b、业务日志的502和504情况

c、cpu的负载情况

d、服务器内存的使用情况

整体总结:从数据上看,平均响应时间稍有提高,502和504超时类错误消失,内存利用率增加,cpu变化不大。其实此类调整,从某种意义上看,相当于增加了一台服务器,多了一个php的池子,利用多实例在服务器层面补齐php-fpm本身的短板,增大服务器资源的利用率。对于结果,业务承接能力肯定增大,至于是不是倍数关系还待测试。

 |
社长"矢量比特",曾就职中软、新浪,现任职小米,致力于DevOps运维体系的探索和运维技术的研究实践. |