某局点升级(nginx变ats,同时去掉前端的nginx负载层),升级之后服务就不正常,硬生生的看着十几万连接,没有流量,各种排错,可谓是把心提到嗓子眼惊心动魄的半小时,虽然做了很好的业
某局点升级(nginx变ats,同时去掉前端的nginx负载层),升级之后服务就不正常,硬生生的看着十几万连接,没有流量,各种排错,可谓是把心提到嗓子眼惊心动魄的半小时,虽然做了很好的业务机制,服务不正常用户可以直接回源,不过对于我们的流量而言肯定是个锯齿了,回顾一下排查过程。
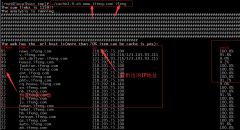
升级过程不说了,升完后对业务配置、健康心跳、磁盘设置、本地回源DNS简单做了检查,没发现问题。接下来就是切流量过来,前端的DNS按照域名哈希将请求分发过来,流量迅速到了100M还在上升,连接数到了几万(域名质量不好,很多动态的,所以也算正常),但过了几分钟流量骤降,一直降到了几M,观察连接数没降反升,内存几乎吃满。

(当前连接数)

(进出流量及cpu、内存、tcp重传1秒刷新动态监控图,内存越跑越满,tcp重传越来越高)
神经马上紧张起来了,先检查DNS是否正常,因为本地回源DNS如果坏掉,会出现这种攒了大量连接无法服务的情况,然而测试发现本地回源DNS服务正常,看来不是简单问题,crt打开多个窗口,开始监测:
tailf /var/log/messages |grep kernel 没有报错,系统层面应该没什么问题。
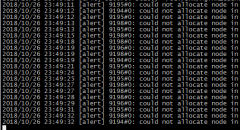
tailf /opt/ats/var/log/trafficserver/diags.log 没有明显报错,只是过一段时间会提示连接太多,丢弃连接,说明业务肯定是不正常了,不过定位不了是哪里的错误。
tstop打开后查看整体的情况,发现正常刷新,但是每次刷新有些数据不能正常显示,内存缓存和硬盘缓存的容量都没有显示,为什么没有显示呢,是设置错误了么,然后再去检查磁盘设置,发现records.config内存缓存设置为内存的一半12G,storge.config设置也没问题,继续检查。
tsar –l 1 监测,磁盘IO都为0,所有的盘都不写盘,于是想到底是因为没有流量导致不写盘的,还是写不了盘导致没有流量的呢,先假设不写盘才没流量的吧,不写盘有两种情况一是盘坏了二是磁盘的权限不对,马上检查,发现所有的数据盘拥有者所有组均为tserver,而且检查了全为裸盘,貌似没有问题。

(权限查看后发现没问题)
tsar –n 1 继续检查下历史数据,发现ats启动的瞬间是有流量的,紧接着流量骤降,而且磁盘刚开始是有IO的,越来越怀疑是硬盘问题但没有证据。后来想,做个测试,干脆不用硬盘,直接上内存,竟然有流量了,而且相对稳定,终于定位出问题了。

(将盘全部注释掉)
继续想,难道所有的硬盘都坏了么,加入一个硬盘试试吧,依旧不行,继续想下去,为什么tstop计算不出缓存呢,于是列出所有磁盘的大小,发现这个局点的每块磁盘居然有将近2T左右,图如下:

(只有一个盘是186.5G,其余的盘都在2T)
继续想可能是磁盘太大了,ats无法加入进来吧,于是更改使用磁盘的大小(300G),重启ats,问题解决,松了一口气,惊心动魄半小时。

(磁盘大小配置更改,直接指定大小)

(更改重启后,业务恢复正常)
“运维网咖社”原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 、作者信息和本声明。否则将追究法律责任。http://www.net-add.com

 |
社长"矢量比特",曾就职中软、新浪,现任职小米,致力于DevOps运维体系的探索和运维技术的研究实践. |