plog是一个用python写的流式计算分析框架,适用于轻量级流式数据的分析场景,大数据场景下大家自然想到使用spark等方案。 拿当前的业务场景看,需要对机器上nginx的流日志进行状态码、
plog是一个用python写的流式计算分析框架,适用于轻量级流式数据的分析场景,大数据场景下大家自然想到使用spark等方案。
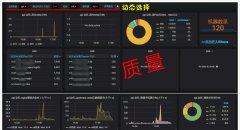
拿当前的业务场景看,需要对机器上nginx的流日志进行状态码、响应时间、QPS的实时分析,通过zabbix展现在grafana里,QPS在1000以内。传统方法是用shell脚本来计算各种数据,然后通过主动或被动模式传到zabbix里,此种方法有很大局限性,一是grep或awk过滤日志时,很难控制好过滤的数量,过滤的多了严重影响性能,可能上一个数据都没计算出来,这一次的计算又得开始了,二是过滤的少了可能丢日志,三是不好控制计算推送周期,总结一句话就是不科学。对于这种数据量不大的流式数据,plog恰巧能解决所有问题,采用流式分析,对数据进行实时计算,通过编写zabbix的sink插件,将计算结果用zabbix_sender推到zabbix。
默认的channel模块支持正则和grok正则的方式匹配,由于日志的复杂性,重新编写了用split分割符的插件进行处理,目前对2xx、3xx、4xx、5xx、qps、request_time、404、499、500、502、504进行了流式监控,详细介绍一下配置部署二开过程。
传统shell处理方式详见之前博客:zabbix_sender主动上传k/v监控nginx日志状态码
一、安装zabbix_sender,不介绍了
二、安装plog模块框架
详见我浪同学的github:https://github.com/SinaMSRE/Plog.git
三、配置编写plog的模块
1、目录结构简单介绍
plog.init start|stop|restart plog.conf plog的配置文件 ./plog channel 流过滤使用的模块 sink 流处理模块 source 流的数据源
2、配置文件plog.conf
[source] source_module=file_source source_file=/data1/logs/nginx/access/default.log #日志文件 source_interval=5 [channel] channel_module=split_channel #新建channel channel_dict_key=status,request_time #定义流数据需要的数据字典的key [sink] interval=60 #流计算的时间间隔 sink_module=zabbix_sink #流计算使用的模块 sink_service=cms_front sink_zabbix_monitor_keys=2xx,3xx,4xx,5xx,qps,request_time,404,499,500,502,504 #zabbix使用的字典键值 sink_zabbix_send_file=/tmp/zabbix_send_info sink_zabbix_sender=/usr/bin/zabbix_sender sink_zabbix_conf=/etc/zabbix/zabbix_agentd.conf [log_config] logging_format=%(asctime)s %(filename)s [funcname:%(funcName)s] [line:%(lineno)d] %(levelname)s %(message)s logging_level=200 logging_filename=/tmp/plog.log
3、channel里split_channel模块的创建编写
日志格式如下:
[17/May/2017:15:59:59 +0800]`-`"GET /e/2017-05-17/zx-ifyfeius8035129.d.html?HTTPS=1&wb7=1 HTTP/1.1"`"Mozilla/5.0 (Linux; Android 6.0.1; MI 5 Build/MXB48T; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/51.0.2704.81 Mobile Safari/537.36 Weibo (Xiaomi-MI 5__weibo__7.4.0__android__android6.0.1)"`302`[183.207.216.230]`-`"-"`0.006`5`-`183.207.216.230`zx.sina.cn`Apache=1734318905510.0083.1460969978688; SINAGLOBAL=1734318905510.0083.1460969978688; ustat=__117.136.46.233_1470561558_0.72156500; genTime=1470561558; wm=3049_0016; ULV=1492129669225:1:1:1:1734318905510.0083.1460969978688:; vt=4; historyRecord={\x22href\x22:\x22https://zx.sina.cn/e/2017-05-17/zx-ifyfeius8042731.d.html?HTTPS=1&wb7=1&wm=3049_0015\x22,\x22refer\x22:\x22\x22}; sina_ucode=YIpQpMYXYI; SUB=_2A250DEfSDeRhGeNG4lQY8yvOzjSIHXVXXnOarDV9PUJbitANLVr_kWt64BftZM-dOtVxSfecCOs95A8jTA..; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WWkK3TP5Fm3eOQho4hT_RMa5NHD95Qf1h.c1Kefeo-RWs4DqcjVi--fiKysi-8si--fiKysi-8si--fiKysi-8si--Xi-iFi-2fSKn4So.0SKzf15tt在./plog/plog/channel目录下创建split_channel.py文件,并编写代码如下:
from plog.channel.base import channel_base
import os
import time
class channel(channel_base):
def __init__(self,channel_dict,source_iter,dict_queue):
self.channel_dict_key = channel_dict["channel_dict_key"].split(",")
self.source_iter = source_iter
self.dict_queue = dict_queue
def parse_line(self):
for line in self.source_iter:
try:
li1 = line.split('`') #定义分隔符
li2 = [] #初始化列表
if li1[4] and li1[8]:
li2.append(li1[4]) #取出日志分割后使用的字段,对应channel_dict_key的status
li2.append(li1[8]) #取出日志分割后使用的字段,对应channel_dict_key的request_time
self.dict_queue.put(dict(zip(self.channel_dict_key,li2))) #对应打成字典
else:
pass
except Exception,e:
print str(e)4、sink里zabbix_sink流处理的编写
模块是已有的,进行重新编码如下:
from plog.sink.base import sink_base
import os
import time
import commands
class sink(sink_base):
def __init__(self, sink_dict):
self.service = sink_dict['sink_service']
self.send_dict = dict.fromkeys(sink_dict['sink_zabbix_monitor_keys'].split(','),0)
self.zabbix_send_file = "_".join((sink_dict['sink_zabbix_send_file'],self.service))
self.zabbix_sender = sink_dict['sink_zabbix_sender']
self.zabbix_conf = sink_dict['sink_zabbix_conf']
self.dealed_total = 0
self.count = 0
self.req_time_count = 0
def calculate_item(self, item): #计算函数
self.count += 1
#host = item['host']
try:
status = item['status']
request_time = float(item['request_time'])
if status[0:1] == "2":
self.send_dict['2xx'] += 1
elif status[0:1] == "3":
self.send_dict['3xx'] += 1
elif status[0:1] == "4":
self.send_dict['4xx'] += 1
elif status[0:1] == "5":
self.send_dict['5xx'] += 1
if status == "404":
self.send_dict['404'] += 1
elif status == "499":
self.send_dict['499'] += 1
elif status == "500":
self.send_dict['500'] += 1
elif status == "502":
self.send_dict['502'] += 1
elif status == "504":
self.send_dict['504'] += 1
self.req_time_count += request_time
except Exception,e:
pass
#print response_code,request_time
def deal_sink(self): #一个周期计算完成后的处理函数
import platform
hostname = platform.uname()[1]
if self.count > 0:
self.send_dict['request_time'] = float(self.req_time_count/float(self.count))
self.send_dict['qps'] = int(self.count/60)
with open(self.zabbix_send_file,"w") as file_handle:
for key in self.send_dict:
info="%s %s_%s %f\n" % (hostname, self.service, str(key), self.send_dict[key])
file_handle.write(info)
self.send_dict[key]=0
self.count = 0
self.req_time_count = 0
cmd = "%s -c %s -i %s" % (self.zabbix_sender, self.zabbix_conf, self.zabbix_send_file)
status,output = commands.getstatusoutput(cmd)处理完成后启动服务,查看zabbix_sender的处理结果如下:

5、将对应的监控项配置到zabbix里再配置到grafana里,不再进行介绍
备注:
1、调试信息可以直接打到log里,/tmp/plog.log;
2、启动时会遇到几个小插曲,用的时候就知道了,需要easy_install安装一个模块,需要改几行代码,留个小惊喜吧。
“运维网咖社”原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 、作者信息和本声明。否则将追究法律责任。http://www.net-add.com

 |
社长"矢量比特",曾就职中软、新浪,现任职小米,致力于DevOps运维体系的探索和运维技术的研究实践. |